Bảo mật dữ liệu kế toán khi sử dụng AI — Từ tiêu chuẩn ISO đến thực hành hàng ngày

Kể cả khi dùng Enterprise plan hoặc API (data không bị train), dữ liệu vẫn rời khỏi hạ tầng nội bộ của bạn. Nó truyền qua internet, được lưu tạm trên server nhà cung cấp (7-30 ngày), và có thể bị truy cập nếu xảy ra breach ở phía provider. Lo ngại này là có cơ sở thực tế, không phải hoang tưởng. Bài này hướng dẫn toàn diện cho kế toán viên — từ tiêu chuẩn ISO/NIST/GDPR đến quy trình thực hành hàng ngày.
Chương 1: Vấn đề thực tế — Tại sao phải lo?
Các rủi ro cụ thể khi kế toán dùng AI
| Rủi ro | Mô tả | Hậu quả |
|---|---|---|
| Data in transit | Dữ liệu truyền từ máy bạn → server AI qua internet | Có thể bị intercept nếu kết nối không an toàn |
| Data at rest | Server AI lưu tạm input/output (7-30 ngày) | Nếu provider bị hack, data của bạn bị lộ |
| Data leakage qua prompt | Nhân viên paste dữ liệu nhạy cảm vào ChatGPT free | Data có thể được dùng để train model |
| Model memorization | LLM có thể "nhớ" dữ liệu training và reproduce | Dữ liệu của người khác có thể bị tiết lộ |
| Insider threat | Nhân viên provider có quyền truy cập logs | Dù có policy, con người vẫn là yếu tố rủi ro |
Con số thực tế
Chương 2: Khung tiêu chuẩn quốc tế
Đây là các tiêu chuẩn chính thống, được các tổ chức kiểm toán lớn (Big 4) và cơ quan quản lý tham chiếu.
ISO 27001:2022 — Annex A Control 8.11 (Data Masking)
Tiêu chuẩn bảo mật thông tin quốc tế. Control 8.11 yêu cầu tổ chức áp dụng data masking thông qua 2 kỹ thuật chính:
- Pseudonymization (Mã hóa giả danh) — Thay thế dữ liệu nhận diện bằng token/mã. Có thể đảo ngược khi cần.
- Anonymization (Ẩn danh hóa) — Xóa hoặc biến đổi không thể đảo ngược. Dữ liệu không thể truy ngược về cá nhân.
Nguồn: ISMS.online — ISO 27001:2022 Annex A Control 8.11
ISO/IEC 42001:2023 — AI Management System (AIMS)
Tiêu chuẩn đầu tiên trên thế giới về quản lý hệ thống AI. Yêu cầu:
- Clause 8.4 — AI System Impact Assessment (AISIA): Đánh giá tác động riêng biệt cho hệ thống AI, tương tự DPIA của GDPR.
- Xác định, đánh giá và giảm thiểu rủi ro AI bao gồm: bias, accountability, và data protection.
- Tích hợp với ISO 27001 (bảo mật) và ISO 27701 (quyền riêng tư).
Nguồn: ISO.org — ISO/IEC 42001:2023 | AWS — AI Lifecycle Risk Management
ISO/IEC 27701:2024-2025 — Privacy Information Management
Bản cập nhật mới bổ sung controls riêng cho AI xử lý dữ liệu cá nhân (PII). Yêu cầu:
- Lọc và loại bỏ/mã hóa PII trước khi đưa vào AI model.
- Cơ chế Data Minimization — chỉ gửi dữ liệu tối thiểu cần thiết.
Nguồn: Certiget — ISO/IEC 27701:2024 Changes
GDPR — Article 4(5) & Recital 26 (Pseudonymization)
GDPR định nghĩa chính thức pseudonymization là: xử lý dữ liệu cá nhân sao cho không thể quy cho một chủ thể cụ thể nếu thiếu thông tin bổ sung, với điều kiện thông tin bổ sung được lưu trữ riêng biệt.
GDPR khuyến khích pseudonymization như một biện pháp kỹ thuật phù hợp (Article 25 — Data Protection by Design).
NIST SP 800-188 & NISTIR 8053 — De-Identification
NIST phân loại các kỹ thuật de-identification:
| Kỹ thuật | Mô tả | Đảo ngược? |
|---|---|---|
| Removal | Xóa hoàn toàn trường nhạy cảm | Không |
| Masking | Thay bằng ký tự lặp (XXXX, 9999) | Không |
| Hashing | Chuyển thành chuỗi hash (SHA-256) | Không (1 chiều) |
| Encryption | Mã hóa bằng key (AES-256) | Có (cần key) |
| Pseudonymization / Tokenization | Thay bằng token, lưu mapping riêng | Có (cần mapping table) |
| Generalization | Làm mờ chi tiết (tuổi → khoảng tuổi) | Không |
| Synthetic Data | Tạo dữ liệu giả có cùng đặc tính thống kê | Không áp dụng |
Nguồn: NIST SP 800-188 | NISTIR 8053
BfDI Germany (2024) — Hướng dẫn AI + DPA
Cơ quan bảo vệ dữ liệu Đức yêu cầu: AI systems phải triển khai real-time data minimization — hệ thống kỹ thuật phải phát hiện và loại bỏ hoặc pseudonymize dữ liệu cá nhân trước khi nó đến AI model.
Nguồn: Anonym.legal — BfDI Guide 2024
Chương 3: Chính sách bảo mật của các nhà cung cấp AI
Thông tin dưới đây được xác minh từ trang chính thức của từng nhà cung cấp. Tuy nhiên, chính sách có thể thay đổi — luôn kiểm tra lại trước khi quyết định.
| Nhà cung cấp | Free/Pro | Enterprise / API | Data Retention | Zero Retention? |
|---|---|---|---|---|
| OpenAI (ChatGPT) | Có thể dùng để train (opt-out được) | KHÔNG train. Data ownership thuộc khách hàng. | API: tối đa 30 ngày (abuse monitoring) | Có (API qualifying orgs) |
| Anthropic (Claude) | Consumer: opt-in training (từ 09/2025) | API: KHÔNG train. Enterprise: hợp đồng riêng. | API: 7 ngày (từ 09/2025, giảm từ 30 ngày) | Có (Zero Data Retention agreement) |
| Google (Gemini) | Có thể dùng để cải thiện sản phẩm | Vertex AI / API: KHÔNG train. | Tùy cấu hình | Tùy hợp đồng |
Nguồn chính thức:
Dù cam kết không dùng data để train model, các provider vẫn: (1) lưu tạm dữ liệu trên server của họ, (2) có nhân viên có thể truy cập logs để debug/abuse monitoring, (3) server của họ có thể bị tấn công. Đây là lý do tại sao các tiêu chuẩn ISO vẫn yêu cầu pseudonymization/masking dù bạn dùng plan nào.
Chương 4: Quy trình Mask → AI → Remap (Pseudonymization)
Đây là quy trình được khuyến nghị bởi cả ISO 27001 (Control 8.11), GDPR (Article 25), và NIST (SP 800-188). Ý tưởng cốt lõi: dữ liệu nhạy cảm không bao giờ rời khỏi máy bạn ở dạng thật.
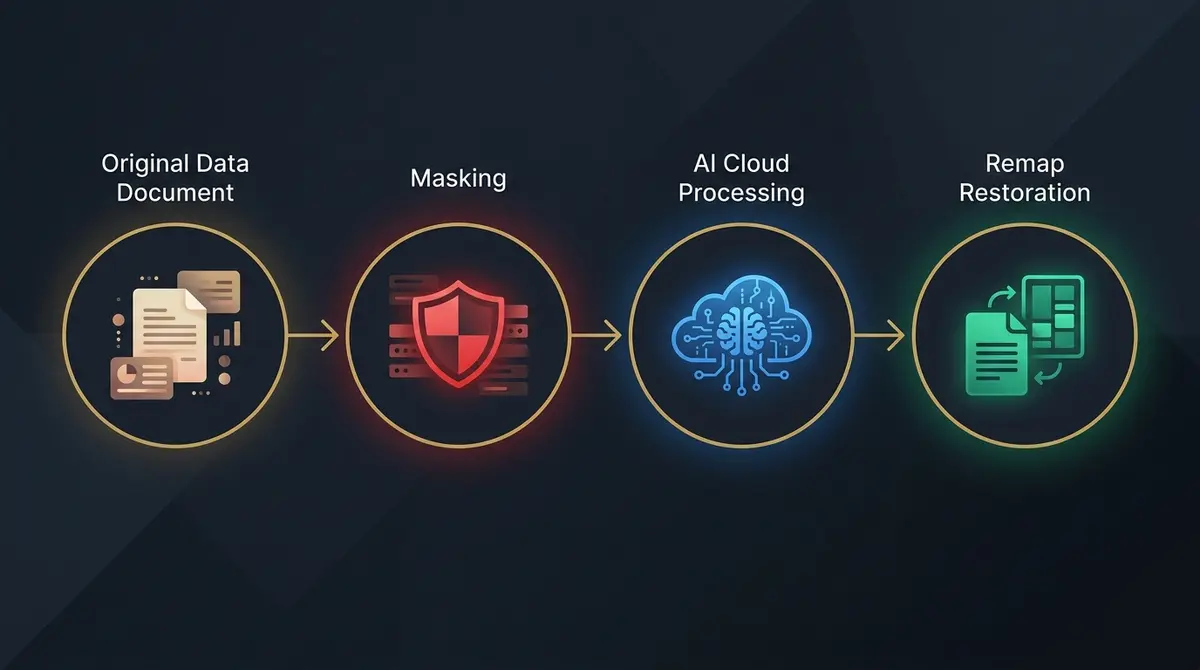
Bước 1: Phân loại dữ liệu (Data Classification)
Trước tiên, xác định trường nào nhạy cảm trong file kế toán:
| Mức độ | Loại dữ liệu | Ví dụ kế toán | Xử lý |
|---|---|---|---|
| Cấm | Bí mật kinh doanh cốt lõi | Công thức giá thành riêng, chiến lược M&A | KHÔNG gửi AI |
| Cao | PII trực tiếp | MST, tên KH, SĐT, số CMND, số TK ngân hàng | Bắt buộc mask/tokenize |
| Trung bình | Dữ liệu tài chính chi tiết | Số dư TK, doanh thu theo KH, lương nhân viên | Nên mask hoặc tổng hợp |
| Thấp | Dữ liệu tổng hợp / cấu trúc | Tổng doanh thu, tỷ lệ %, cấu trúc TK | Có thể gửi trực tiếp |
Bước 2: Tạo Mapping Table (bảng tra cứu)
Tạo 1 file Excel riêng, lưu tại máy local, KHÔNG upload lên AI:
| Trường | Giá trị gốc | Token thay thế |
|---|---|---|
| Tên công ty | Công ty TNHH Thiên An | KH_001 |
| MST | 0312345678 | MST_001 |
| SĐT | 0901234567 | SDT_001 |
| Số TK ngân hàng | 1234567890123 | TK_001 |
| Tên NV | Nguyễn Văn A | NV_001 |
| CMND | 079123456789 | (không gửi AI — xóa khỏi file) |
Bước 3: Gửi file đã mask cho AI
File gửi cho AI chỉ chứa: KH_001, MST_001, SDT_001... cùng với số liệu tài chính. AI xử lý bình thường vì:
- Cấu trúc dữ liệu được giữ nguyên
- Các phép tính, công thức, logic kế toán không bị ảnh hưởng
- AI không cần biết "Công ty Thiên An" để tính BCTC
Bước 4: Remap — Khôi phục data gốc
Sau khi AI trả kết quả, dùng Find & Replace (hoặc VLOOKUP) với mapping table để thay KH_001 → "Công ty TNHH Thiên An".
Dữ liệu nhạy cảm (tên thật, MST thật) chưa bao giờ rời khỏi máy bạn. Dù server AI bị hack, kẻ tấn công chỉ thấy "KH_001" — vô nghĩa nếu không có mapping table (nằm ở máy local).
Chương 5: Các kỹ thuật thực hành (Tricks) cho kế toán
Các kỹ thuật trong phần này là tips & tricks thực hành, được tổng hợp từ kinh nghiệm cộng đồng và best practices ngành. Chúng không phải nội dung từ tài liệu ISO/NIST chính thống, mà là cách áp dụng thực tế dựa trên nguyên tắc của các tiêu chuẩn đó.
Trick 1: Đổi số — Nhân/chia hệ số cố định
Thay vì gửi số liệu thật, nhân tất cả số tiền với 1 hệ số (ví dụ: x1.37). Các tỷ lệ, xu hướng, cân đối vẫn giữ nguyên.
KHÔNG gửi AI
- — Doanh thu: 15,800,000,000
- — Giá vốn: 11,060,000,000
- — Lãi gộp: 4,740,000,000
- — Biên lãi gộp: 30%
Có thể gửi AI
- — Doanh thu: 21,646,000,000
- — Giá vốn: 15,152,200,000
- — Lãi gộp: 6,493,800,000
- — Biên lãi gộp: vẫn 30%
Ưu điểm: Tỷ lệ %, trend, cân đối TS = NV + VCSH vẫn đúng. AI phân tích bình thường.
Hạn chế: Nếu đối thủ biết ngành + quy mô, có thể suy đoán ngược. Nên kết hợp với mask tên.
Trick 2: Token hóa thủ công bằng Excel
Dùng Find & Replace hoặc VLOOKUP để thay thế hàng loạt trước khi gửi:
// Sheet "Mapping" (file riêng, KHÔNG upload AI)
A1: Tên gốc B1: Token
A2: Cty Thiên An B2: KH_001
A3: Cty Phát Đạt B3: KH_002
A4: Nguyễn Văn Minh B4: NV_001
// Sheet "Data gửi AI" — dùng VLOOKUP
=VLOOKUP(A2, Mapping!A:B, 2, FALSE)
→ "KH_001" thay cho "Cty Thiên An"
Trick 3: Chỉ gửi cấu trúc, không gửi data
Khi cần AI giúp viết công thức, tạo template, hoặc thiết kế quy trình — gửi mô tả cấu trúc thay vì data thật:
SAI
- — 'Đây là bảng lương tháng 4.'
- — 'Nguyễn Văn A lương 25tr,'
- — 'Trần Thị B lương 18tr...'
- — 'Hãy tính thuế TNCN.'
ĐÚNG
- — 'Tôi có bảng lương với các cột:'
- — 'Mã NV, Lương gross, Phụ cấp, BHXH, Thuế TNCN.'
- — 'Hãy viết công thức Excel tính thuế TNCN theo biểu lũy tiến.'
- — 'Tôi sẽ áp dụng vào data thật.'
Trick 4: Tách file — Gửi từng phần
Thay vì upload 1 file có đầy đủ thông tin (tên KH + MST + số tiền + SĐT), tách ra:
- File 1: Chỉ có mã KH + số tiền (gửi AI phân tích)
- File 2: Mã KH + tên thật + MST (giữ local, dùng để merge sau)
AI xử lý File 1, bạn merge kết quả với File 2 bằng VLOOKUP.
Trick 5: Dùng dữ liệu mẫu trước, data thật sau
- Bước 1: Tạo data mẫu (hoặc nhờ AI tạo) → gửi AI để xây dựng quy trình/template/công thức.
- Bước 2: Khi quy trình đã ổn, áp dụng vào data thật offline trên máy local.
Chương 6: Công cụ hỗ trợ
Microsoft Presidio (Open-source)
Framework mã nguồn mở của Microsoft, chuyên phát hiện và ẩn danh PII trong text, hình ảnh, và structured data.
- Analyzer: Phát hiện PII bằng NER + regex + checksum (tên, SĐT, email, MST, số thẻ...)
- Anonymizer: Thay thế PII bằng token, mask, mã hóa, hoặc xóa
- Deanonymizer: Khôi phục data gốc (reversible)
- Hỗ trợ đa ngôn ngữ, có thể custom thêm recognizer cho MST Việt Nam
Nguồn: GitHub — microsoft/presidio | Presidio Documentation
# Ví dụ Presidio với Python
from presidio_analyzer import AnalyzerEngine
from presidio_anonymizer import AnonymizerEngine
analyzer = AnalyzerEngine()
anonymizer = AnonymizerEngine()
text = "Công ty Thiên An, MST 0312345678, liên hệ 0901234567"
results = analyzer.analyze(text=text, language="en") # detect PII
masked = anonymizer.anonymize(text=text, analyzer_results=results)
# → "Công ty <PERSON>, MST <PHONE_NUMBER>, liên hệ <PHONE_NUMBER>"
Các công cụ khác (Open-source / Enterprise)
| Công cụ | Nhà phát triển | Đặc điểm |
|---|---|---|
| Google DLP API | Google Cloud | Phát hiện + mã hóa PII ở quy mô lớn, có format-preserving encryption |
| AWS Macie | Amazon | Tự động phát hiện PII trong S3, phân loại dữ liệu |
| spaCy + custom NER | Open-source | Train model nhận diện entity tiếng Việt (tên, địa chỉ, MST) |
| Protecto.ai | Protecto | Chuyên tokenize PII trước khi gửi LLM, có reversible mapping |
Giải pháp đơn giản cho kế toán (không cần code)
Nếu không dùng được Presidio hay code Python, có thể làm thủ công trong Excel:
- Tạo sheet "Mapping" — liệt kê tất cả tên KH, MST, SĐT — gán mã (KH_001, MST_001...)
- Copy data sang sheet "Gửi AI" — Find & Replace hàng loạt (Ctrl+H)
- Upload sheet "Gửi AI" cho AI xử lý
- Kết quả từ AI — Find & Replace ngược lại bằng mapping
Chương 7: Case Studies thực tế
3 vụ rò rỉ trong 20 ngày
Gì đã xảy ra: Kỹ sư Samsung paste source code chip bán dẫn vào ChatGPT để debug. Một nhân viên khác upload code kiểm tra lỗi thiết bị. Người thứ ba chuyển biên bản họp nội bộ thành text rồi đưa vào ChatGPT để tóm tắt.
Hậu quả: Samsung cấm toàn bộ generative AI trên thiết bị công ty. Dữ liệu đã gửi không thể thu hồi — nó có thể đã được dùng để train model (thời điểm đó ChatGPT free mặc định train).
Bài học cho kế toán: Nếu bạn paste bảng lương, MST khách hàng, hoặc số liệu tài chính vào ChatGPT free — nó có thể được lưu và dùng để cải thiện model. Hãy dùng API hoặc Enterprise + mask data.
Nguồn: TechCrunch | Bloomberg
64 triệu hồ sơ ứng viên bị lộ
Gì đã xảy ra: AI chatbot tuyển dụng của McDonald's bị khai thác do lỗi bảo mật — password bảo vệ là "123456". Hơn 64 triệu hồ sơ ứng viên (tên, SĐT, email, thông tin cá nhân) bị truy cập trái phép.
Bài học: AI chatbot xử lý dữ liệu nhạy cảm cần bảo mật ở cả tầng ứng dụng, không chỉ dựa vào cam kết của nhà cung cấp AI.
225,000+ tài khoản OpenAI bị lộ trên dark web
Gì đã xảy ra: Malware (LummaC2 và các loại khác) đánh cắp credentials OpenAI từ máy người dùng. Hơn 225,000 bộ thông tin đăng nhập bị rao bán trên dark web. Nếu tài khoản OpenAI chứa lịch sử chat có dữ liệu nhạy cảm — tất cả đều bị lộ.
Bài học: Bảo mật không chỉ ở phía provider — máy tính của bạn cũng là điểm yếu. Bật 2FA, không lưu dữ liệu nhạy cảm trong chat history.
Công ty TNHH ABC — 20 nhân viên, kế toán dùng Claude API
Tình huống: Kế toán cần AI giúp phân tích công nợ 50 khách hàng, tìm overdue và đề xuất follow-up.
Quy trình áp dụng:
- Export bảng công nợ từ phần mềm kế toán
- Trong Excel: thay tên KH → KH_001~KH_050, xóa cột MST và SĐT
- Upload file đã mask lên Claude API
- Claude phân tích: KH_012 overdue 90 ngày, KH_035 overdue 60 ngày...
- Kế toán dùng mapping table: KH_012 = Cty Minh Phát → gọi điện đòi nợ
Kết quả: AI phân tích chính xác, không có tên công ty hay MST nào rời khỏi máy nội bộ.
Đây là ví dụ mô phỏng để minh họa quy trình, không phải case study thực từ công ty cụ thể.
Chương 8: Ma trận quyết định — Khi nào cần bảo vệ mức nào?
| Tình huống | Mức bảo vệ | Hành động |
|---|---|---|
| Hỏi AI cách hạch toán TK 331 | Thấp | Gửi trực tiếp — không có dữ liệu nhạy cảm |
| Nhờ AI viết công thức Excel | Thấp | Gửi cấu trúc cột, dùng data mẫu |
| Phân tích doanh thu theo khu vực (tổng hợp) | Trung bình | Có thể gửi nếu dùng API/Enterprise. Mask tên KH nếu có |
| Đối soát công nợ chi tiết theo KH | Cao | Bắt buộc mask tên KH, MST, SĐT. Dùng token (KH_001...) |
| Tính lương, thuế TNCN từng nhân viên | Cao | Mask tên NV, CMND, số TK. Hoặc chỉ gửi cấu trúc + công thức |
| Upload sổ phụ ngân hàng gốc | Cấm | KHÔNG upload bản gốc. Mask số TK, tên đối tác, số dư chi tiết |
| Upload hợp đồng có thông tin bảo mật | Cấm | KHÔNG upload. Tóm tắt nội dung cần hỏi, bỏ thông tin nhạy cảm |
Chương 9: Checklist bảo mật trước khi đưa dữ liệu vào AI
Đây là checklist 10 điểm — đi qua từng câu hỏi, nếu KHÔNG đạt thì làm theo cột "Hành động".
| # | Kiểm tra | Nếu KHÔNG đạt |
|---|---|---|
| 1 | Tôi đang dùng plan/kênh nào? (Free, Pro, Enterprise, API) | Nếu Free → cực kỳ cẩn thận, data có thể bị train |
| 2 | File có chứa tên thật (KH, NV, đối tác)? | → Thay bằng mã (KH_001, NV_001...) |
| 3 | File có MST, CMND, số TK ngân hàng? | → Xóa hoặc mask (MST_001, XXXX...) |
| 4 | File có SĐT, email cá nhân? | → Xóa — AI không cần SĐT để phân tích kế toán |
| 5 | Số liệu tài chính có nhạy cảm ở mức chiến lược? | → Nhân hệ số hoặc chỉ gửi tỷ lệ % |
| 6 | Tôi có cần AI biết tên thật để xử lý? | 99% câu trả lời là KHÔNG — AI chỉ cần cấu trúc + số |
| 7 | Mapping table có được lưu riêng, local? | → KHÔNG upload mapping table lên AI |
| 8 | Chat history có bật auto-save? | → Tắt hoặc xóa sau khi dùng (phòng bị hack TK) |
| 9 | Có bật 2FA cho tài khoản AI? | → Bật ngay — 225K tài khoản OpenAI từng bị lộ do malware |
| 10 | Đây có phải dữ liệu bị cấm chia sẻ theo hợp đồng/NDA? | → KHÔNG gửi AI dưới bất kỳ hình thức nào |
Tóm tắt: 4 lớp bảo vệ
Bảo mật dữ liệu kế toán khi dùng AI không phải chọn giữa "dùng" và "không dùng". Là chọn giữa "dùng đúng cách" và "dùng cẩu thả". Cùng một AI tool — một bên giúp bạn x5 năng suất, bên kia khiến bạn vỡ trận khi server provider bị hack.
Bạn đang ở mức nào? Quiz 5 câu
Nguồn tham chiếu
Tiêu chuẩn chính thống
- ISO 27001:2022 Annex A Control 8.11 — Data Masking
- ISO/IEC 42001:2023 — AI Management Systems
- ISO/IEC 27701:2024 — Privacy + AI Updates
- NIST SP 800-188 — De-Identifying Government Datasets
- NISTIR 8053 — De-Identification of Personal Information
- AWS — ISO 42001 AI Lifecycle Risk Management
Chính sách nhà cung cấp AI
- OpenAI Enterprise Privacy
- OpenAI Business Data Privacy
- Anthropic Privacy Center — Model Training
- BfDI Germany — DPA + AI Compliance Guide 2024
Case studies & báo cáo
- TechCrunch — Samsung bans ChatGPT after data leak (2023)
- Bloomberg — Samsung bans generative AI (2023)
- Wald.ai — ChatGPT Data Leaks Overview 2023-2024
- Tech.co — AI Chatbots Business Data Risks
- IBM Cost of a Data Breach Report 2024-2025
Công cụ & hướng dẫn kỹ thuật
- Microsoft Presidio — PII Detection & Anonymization
- Presidio Documentation
- Google Cloud — Sensitive Data Protection / Pseudonymization
- Kiteworks — Prevent LLM Data Leakage
- DZone — Secure LLM Usage With Reversible Data Anonymization
- Sigma AI — Building LLMs with Sensitive Data: Practical Guide
Nếu bạn muốn đi sâu hơn vào cách dùng AI cho kế toán theo chuẩn bảo mật quốc tế — từ thiết lập quy trình Mask → AI → Remap, viết SOP nội bộ, đến đào tạo nhóm — hãy tìm hiểu tại X5 Academy, nơi tôi đang dạy chính những gì mình áp dụng cho doanh nghiệp mỗi ngày.
Mọi thông tin ISO/NIST/GDPR đều có nguồn tham chiếu. Phần "Tricks" được ghi rõ là kinh nghiệm thực hành. Cập nhật: 05/2026.